Failover
Failover is a process of moving active Vsite(s) from the failed unit to the Peer unit when one of the units serving requests is in the Failed state. The Peer unit should be in Active state to take over the active Vsite(s) from the failed unit. On a failover, the Peer unit assumes the active Vsite(s) of the failed unit and continues to process the traffic until the failed unit is restored.
Failover can occur in three ways:
- Link Down – If the parameter Monitor Link for WAN, LAN and Management is selected in the ADVANCED > High Availability page, and when the link is down for any one of the interfaces being monitored, the system goes into the Failed state.
- Inability to Serve Traffic – Instability in any traffic processing module which prevents it from serving traffic will cause the system to go into the Failed state.
- Lost Heartbeat – When the backup unit has not received a heartbeat from the primary unit for nine (9) seconds, it concludes that the primary unit is down or dead and it executes failover.
Failover in Automatic Mode
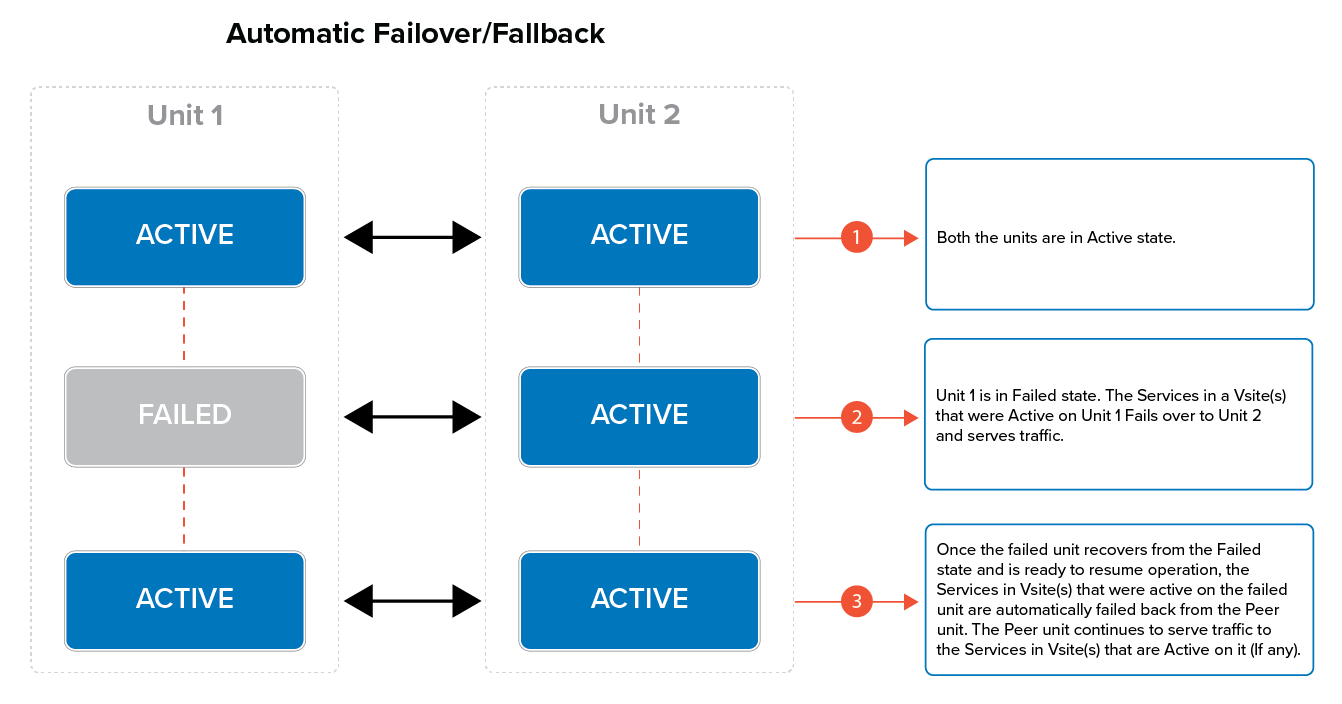
When the unit that is active and handling traffic fails, the active Vsite(s) automatically fails over to the Peer unit. The Peer unit assumes the Services in Vsite(s) from the failed unit and continues to process the traffic until the failed unit is restored.
Failover in Manual Mode
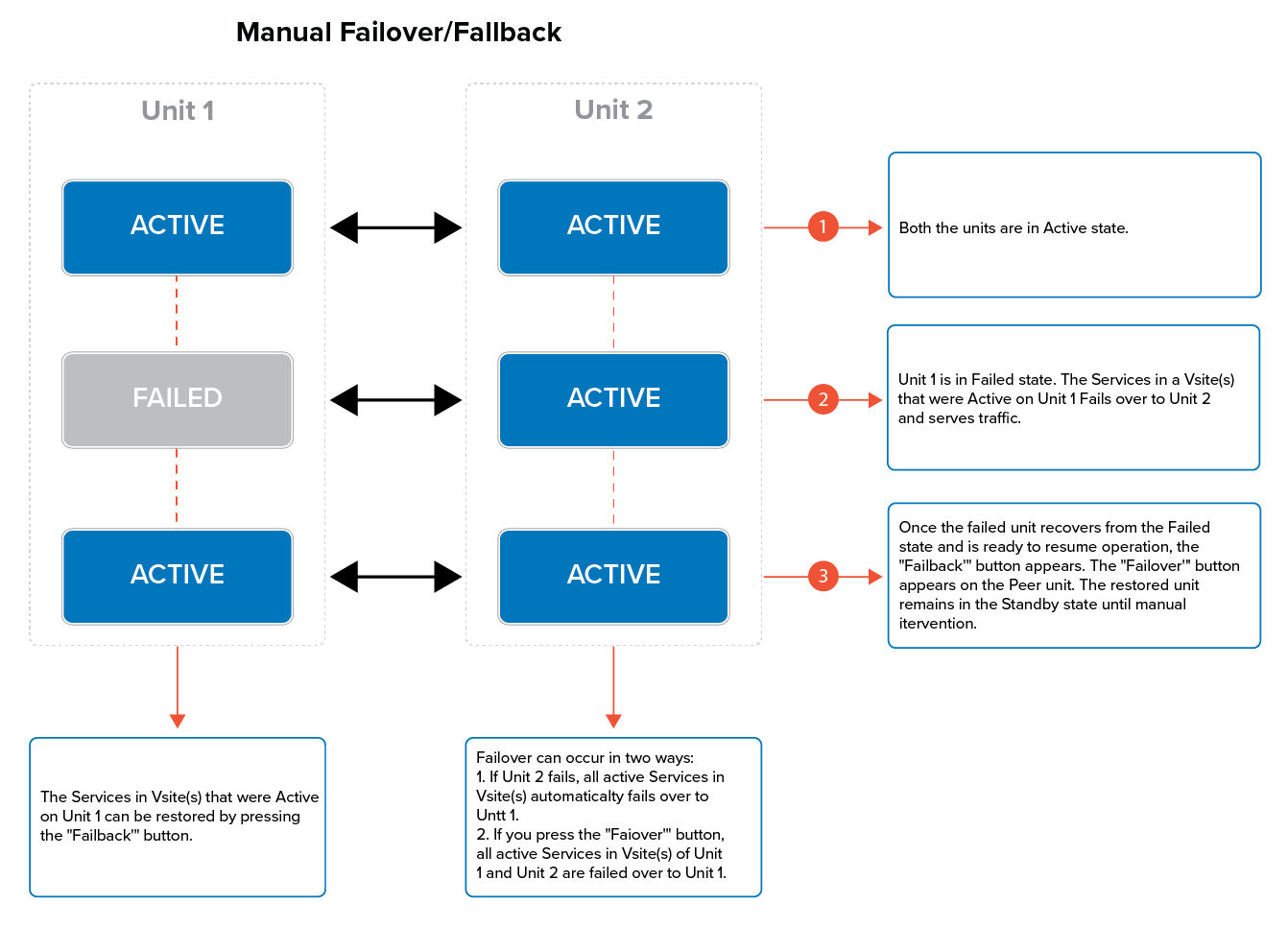
Failover in manual mode occurs in two ways. They are:
- When one of the units serving traffic fails.
- Clicking the Failover button on one of the units.
The first case is similar to the automatic failover. When the unit that is active and handling traffic fails, the active Vsite(s) automatically fails over to the Peer unit. The Peer unit assumes the Vsite(s) of the failed unit and continues to process traffic.
In the second case, you can force a failover on one of the units by clicking the Failover button in the Clustered Systems section. The unit switches to the Standby state and the Peer unit assumes the Services in Vsite(s) from the unit and continues to process traffic.
Failback
Failback restores functioning Vsite(s) that have failed over from the failed unit to the Peer unit. When the failed unit returns from the Failed state to the Active state (that is, it can now actively serve application requests), the Vsite(s) that were Active on the failed unit before failover are automatically failed back (released) from the Peer unit.
Failback in Automatic Mode
When the failed unit recovers from the Failed state and is ready to resume operation, the Vsite(s) that were Active on the failed unit automatically fails back to the restored unit, and continues to serve traffic. The Peer unit continues to serve traffic to the Vsite(s) that are Active on it (if any).
Failback in Manual Mode
Failback in the manual mode occurs in two ways. They are:
- Clicking the Failback button on the backup unit.
- If the Peer unit fails and the other unit is in Standby/Active state
In Manual mode, the Peer unit remains Active even if the failed unit restores from the Failed state and is ready to resume operation. You need to click on the Failback button in the Clustered Systems section of the Peer unit to resume operation on the other unit.
In the second case, the other unit automatically resumes operation if the Peer unit fails. This can occur only when the failed unit is not in Failed state and is ready to resume operation.